CUDA에서 말하는 Stream은 GPU 상에서 Issue 순서로 수행되는 동작들의 Sequence를 말한다.
CUDA에는 여러 개의 Stream이 존재할 수 있으며, 서로 다른 Stream들은 동시에 수행할 수 있다. 일반적으로 여러 Stream을 사용하지 않는 다면, Default Stream(a.k.a stream 0)에서 수행된다. 하나의 Stream 내에서의 동작은 대부분 Host와 GPU에서 synchronous 하게 동작하지만, 'cudaMemcpy*Async'/cudaMemset*Async'와 같이 Asynchronous 동작을 의도하는 경우에는 synchronous 하게 동작하지 않는다.
아래의 동작들은 동시에 수행될 수 있는 것들이다.
1. CUDA Kernel
2. cudaMemcpyAsync (Host to Device)
3. cudaMemcpyAsync (Device to Host)
4. Operation on the CPU
다만, 동시에 수행하기 위해서는 CUDA 동작들은 서로 다른 Stream안에 존재해야하며, 'cudaMemcpyAsync'의 경우 'pinned' memory에 할당된 영역을 접근할 때 가능하다.
[1]에서 소개하는 Pinned memory를 살펴보자. 아래와 같이 Pinned Memory를 설명하고 있다.
Host (CPU) data allocations are pageable by default. The GPU cannot access data directly from pageable host memory, so when a data transfer from pageable host memory to device memory is invoked, the CUDA driver must first allocate a temporary page-locked, or “pinned”, host array, copy the host data to the pinned array, and then transfer the data from the pinned array to device memory, as illustrated below. [1]
즉, Host에서의 데이터 할당은 기본적으로 pageable이다. Pageable 하다는 이야기는 현재 해당 Page가 메인메모리에 존재하지 않아, 디스크로부터 가져와야 하는 Page fault가 발생할 수 있기 때문이다. GPU는 Page fault 발생여부를 알 수 없다. 그러기 때문에 Host 내부에 임시의 Pinned-memory 영역으로 가져온 후, Device로 전송한다. Host 할당 영역이 애초에 Pinned Memory(No page out)이라면 중간과정이 없기 때문에 일반적으로 전송속도가 더 빠르다. 다만, OS가 메인 메모리 상에서 모든 영역을 할당해야 하므로 비용적인 측면에서 크다.
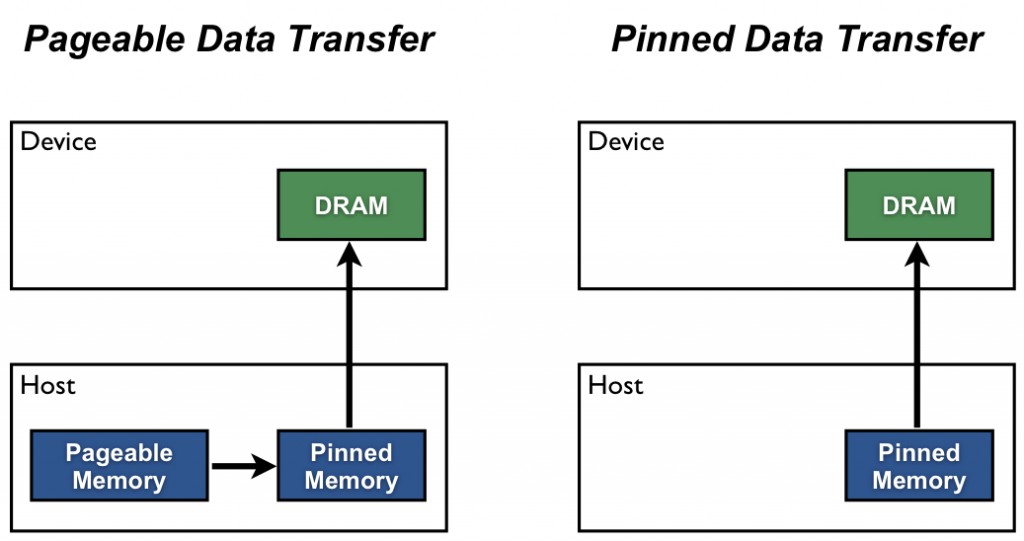
아래와 같은 명령어를 사용하여 Pinned Memory를 사용한 영역을 할당 혹은 해체를 수행할 수 있다.
// allocation Page-locked memory region
cudaError_t cudaMallocHost(void **devPtr, size_t count);
// free allocated memory region
cudaError_t cudaFreeHost(void *ptr);
아래 두 코드는 Sychrounous execution과 Potentially overlapped execution을 수행하는 예제를 보여준다.
Sychronous execution은 default stream만 사용하며, 각 Memcpy는 pageable memory 영역에서 이뤄진다.
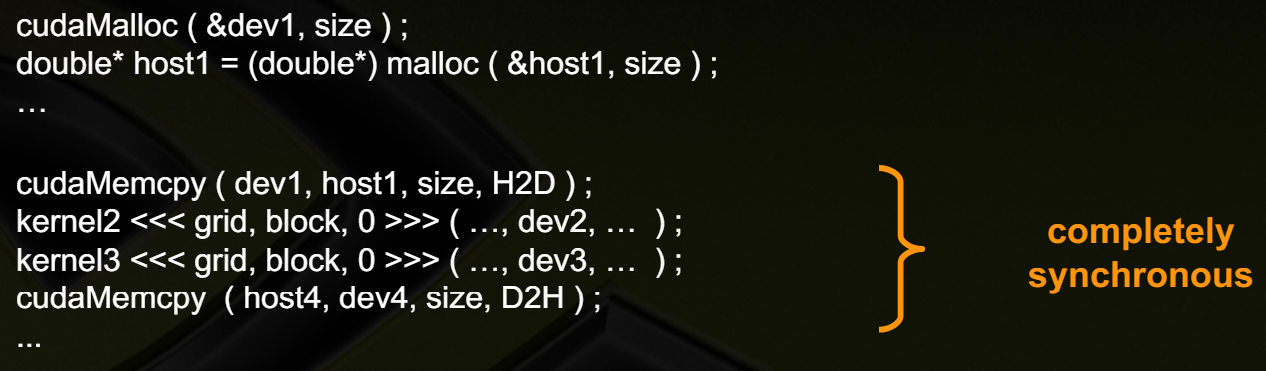
Potentially overlapped execution에서는 4개의 stream을 사용하며 각 stream 마다 수행하는 동작들이 존재한다.
stream1 :: cudaMemcpyAsync
stream2 :: kernel2
stream3 :: kernel3
stream4 :: cudaMemcpyAsync

위와 같이 동시에 수행 가능하므로 이를 관리하기 위한 synchronization 명령어들이 존재한다.
1. Synchronize Everything :: 'cudaDeviceSynchronize()'
> 이전에 이슈 된 모든 CUDA Call이 끝날 때까지 기다린다.
2. Synchronize w.r.t a specific stream :: 'cudaStreamSynchronize(streamid)
> 이전에 특정 stream에 이슈된 모든 CUDA Call이 끝날 때까지 기다린다.
3. Synchronize using Events :: 'cudaEventRecodd(event, streamid)', 'cudaEventSynchronize(event)', cudaStreamWaitEvent(stream, event)', 'cudaEventQuery(event)
> Stream들 안에서 특정 event를 만들어서 Synchronization을 수행할 수 있다. 자세한 내용은 아래 예제를 보자.
stream 1 :: 'cudaMemcpyAsync (d_in, in_size, H2D, stream1) -> event // event로 등록
stream 2 :: 1. 'cudaMemcpyAsync (out, d_out, size, D2H, stream2);
2. wait event
3. kernel<<<,,, stream2>>>(d_in, d_out);
stream 2의 동작이 2번 wait event에서 stream1의 동작을 기다린 다음, 3번 kernel를 실행하도록 할 수 도 있다.

아래와 같은 동작은 implicit synchronization으로 수행된다.

Kernel 자체를 동시에 여러 개 수행하는 것은 GPU Utilization을 높이는 데 도움이 될 수 있다. 그런데 여러 Kernel을 돌리려면 작은 resource를 사용하면서, 긴 시간 동안 수행되는 kernel들이 필요하다. kernel을 수행하기 위해 필요한 자원들이 있기 때문이다. 해당 문서[2]에서도 아래와 같이 4개 이상의 Kernel를 동시에 돌리는 건 어렵다고 한다.
It is difficult to get more than 4 kernels to run concurrently [2]
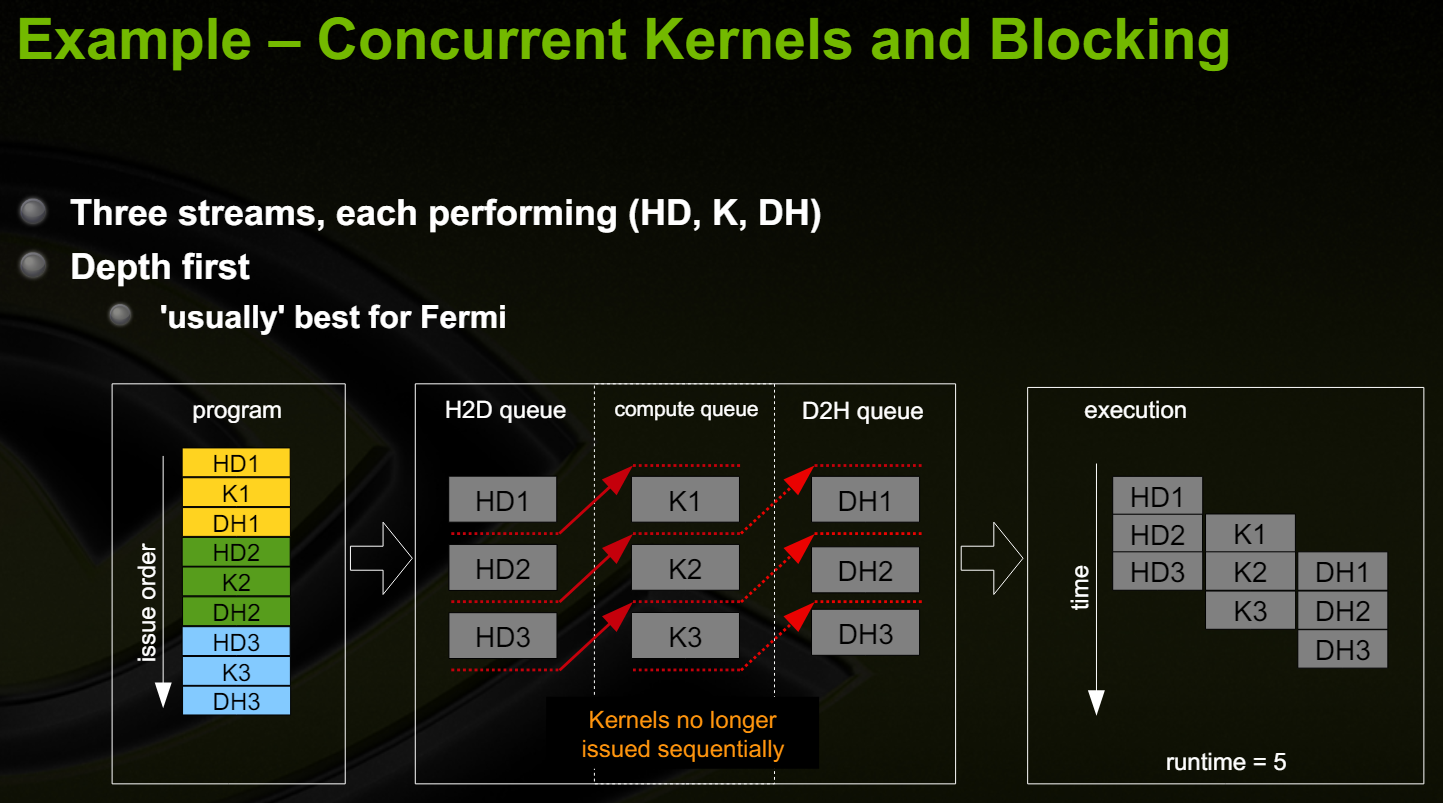
Fermi hardware에는 3개의 Queue가 존재한다. 1개의 Compute Engien Queue와 2개의 Copy Engine queue(one for H2D and one for D2H))가 존재한다.
CUDA 동작은 명령어들이 Issue 되는 순서에 따라 HW에 dispatch 된다.
아래와 같이 program 순서가 Depth first로 수행할 때 가장 성능이 좋다.
데이터를 구분하여 같은 커널을 여러 Stream에 수행하도록 하면, Host to Device 혹은 Device to Host로 데이터를 전송할 때, Kernel를 수행할 수 있다. 연산과 통신을 동시에 수행하는 기법을 double buffering이라 한다.
*Reference
[1] : https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
How to Optimize Data Transfers in CUDA C/C++ | NVIDIA Technical Blog
In the previous three posts of this CUDA C & C++ series we laid the groundwork for the major thrust of the series: how to optimize CUDA C/C++ code. In this and the following post we begin our…
developer.nvidia.com
[2] : https://developer.download.nvidia.com/CUDA/training/StreamsAndConcurrencyWebinar.pdf
'IT_Study > CS_Study' 카테고리의 다른 글
| [Parallel Computing] (23) Shared Memory (0) | 2024.05.28 |
|---|---|
| [Parallel Computing] (22) Optimization for GPUs (0) | 2024.05.28 |
| [Parallel Computing] (20) CUDA (0) | 2024.05.26 |
| [Parallel Computing] (19) Register Allocation (0) | 2024.05.26 |
| [Parallel Computing] (18) OpenCL (0) | 2024.05.26 |


댓글