OpenCL은 Open Computing Language로써 이종 간의 병렬 컴퓨팅(heterogeneous parallel computing)을 위한 병렬 프로그래밍 모델이다. API, Libraries, a runtime system을 지원한다.
모바일 장치에서부터 수퍼컴퓨터까지 다양한 장치를 지원하며, 서로 다른 아키텍처에서도 같은 코드로 수행가능하다. 다만 아키텍처별로 최적화 포인트가 다르기 때문에 성능은 동일하지 않다.
OpenCL은 Host program 과 OpenCL program의 조합으로 구성된다. OpenCL program은 Kernel들의 모음으로 구성되어 있다.
Host Program은 Host에서 수행되며, kernel 실행을 관리한다.
Kernels은 Compute devece(eg, GPU)에서 수행되는 코드의 단위로, 많은 Instance를 생성하여 data parallelism을 활용 할 수 있다.
두 Host Program 과 Kernel들은 모두 병렬적으로 동작한다.
OpenCL Platform model은 아래 그림과 같이 하나의 Host와 하나 혹은 여러 개의 Compute Devices(eg, GPU)로 구성된다. 하나의 Compute Device에는 여러 개의 Compute Unit(eg, SM)이 존재하고, 하나의 Compute Unit에는 여러 개의 Processing Element(eg, ALU in a SM)가 존재한다.
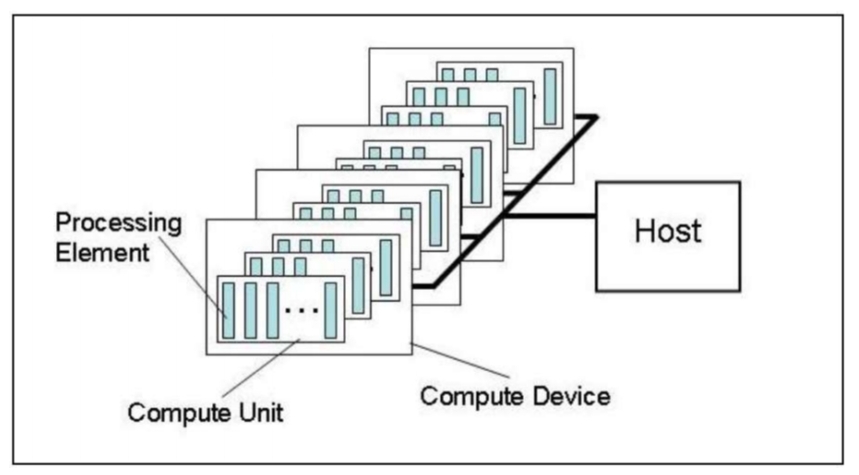
Work-item은 OpenCL 장치에서 실행되는 가장 기본 단위이다. Kernel들은 이 work-items들에서 수행된다. Workgroup은 여러 개의 Work-item들을 모아둔 것을 말한다. Kernel들을 실행할 때, work-item들을 얼마나 수행할 지, 하나의 Workgroup에는 몇 개의 Work-item들을 둘 것인지 결정해야 한다. 아래 그림은 workitem을 1024x1024로 지정하고, 하나의 workgroup마다 128x128개의 workitem을 가지도록 구성한 것이다.
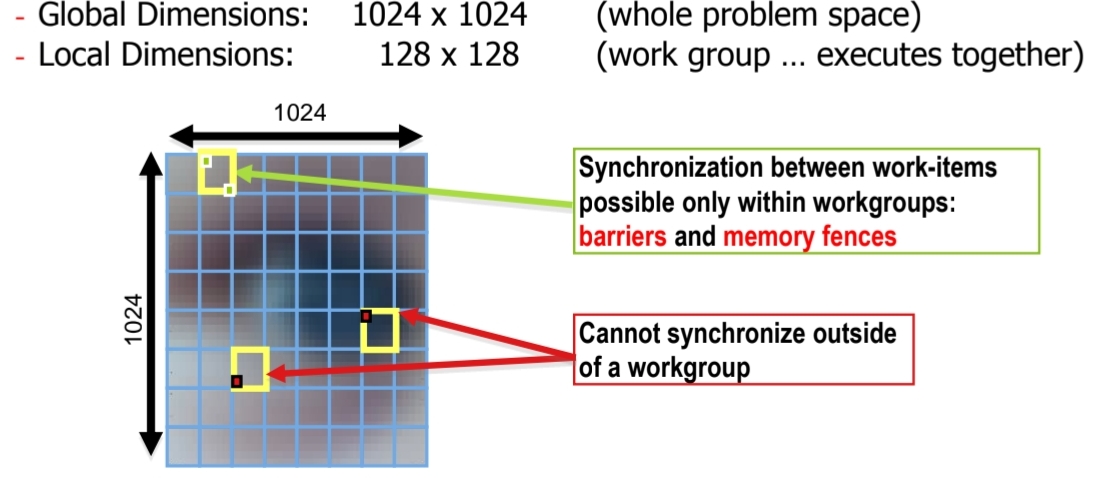
특정적인 점은 Workgroup 간에는 synchronization을 수행할 수 없고, Workgroup 내부는 가능하다는 것이다.
OpenCL Memory Model은 아래 그림과 같다.
실행 단위인 Work-item마다 각자의 고유의 메모리(Private Memory)가 존재한다. Work-item의 모음인 Workgroup 내에서 공유하는 Local Memory가 있다. 그리고 Workgroup 간에 공유하는 Global/Constant Memory가 존재한다.

아래는 vector addtion에 대한 OpenCL Kernel 예시이다.
Kernel에는 해당 함수가 Kernel임을 알리는 '__kernel' 키워드와 해당 변수가 Compute device의 global memory에 존재한다는 '__global' 키워드 그리고 work-item의 index를 읽어오는 'get_global_id(0)'이 추가되었다. 이 work-item index에 따라 work-item이 수행해야할 테스크가 결정된다.
// Host C code
void vec_add(int n, const float *a, const float *b, float *c){
int i;
for (i=0;i<n;i++)
c[i] = a[i] + b[i];
}
// OpenCL Kernel
__kernel void vec_add(__global const float *a,
__global const float *b,
__global float *c){
int id = get_global_id(0);
c[id] = a[id] + b[id];
}
이렇듯 각 work-item들은 하나의 Program으로 여러 데이터를 처리하는 SPMD(SIngle Program Multiple Data) 형태를 가지고 있다.
그러면 실제 코드가 어떻게 실행되는 지 살펴보자. 아래 그림은 OpenCL에서 kernel을 수행하기 위한 흐름을 나타내었다.
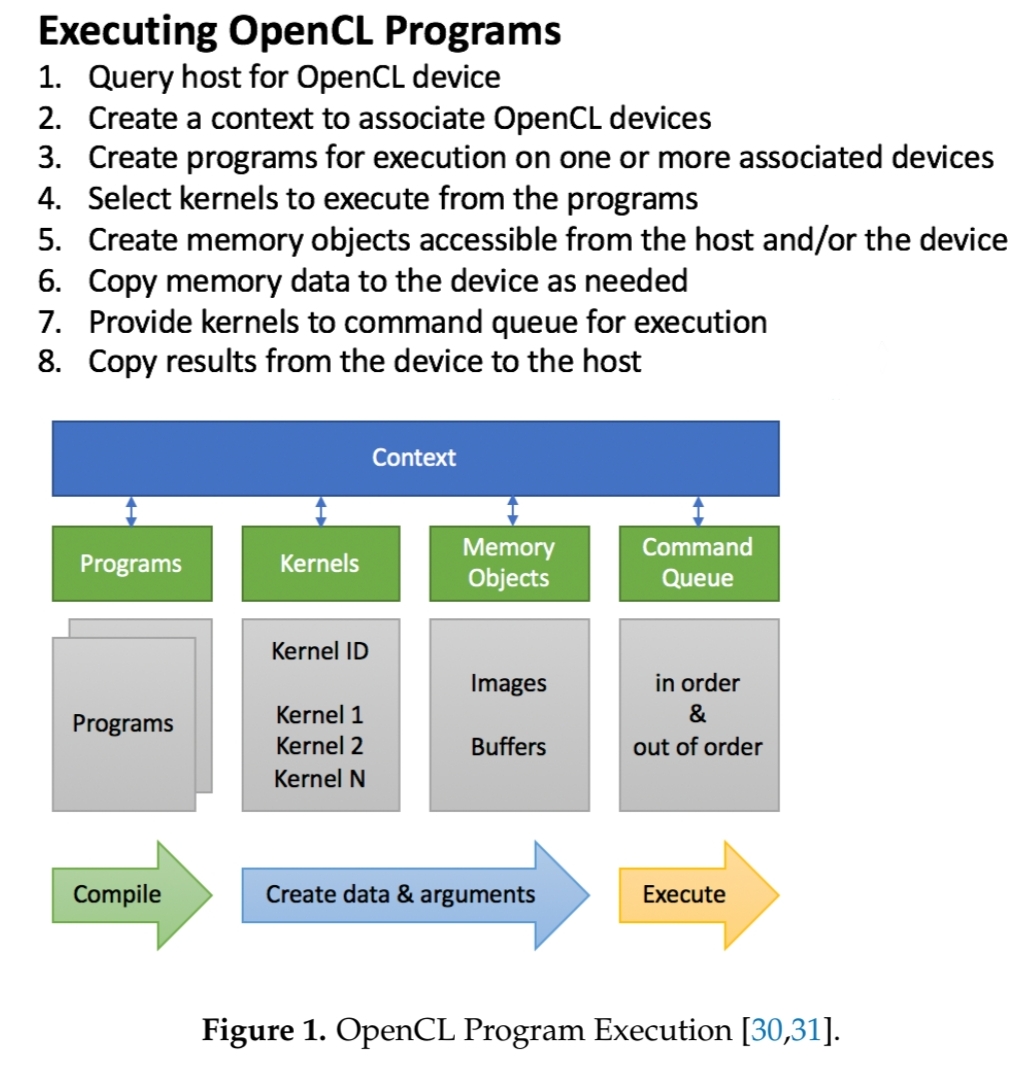
// 0. initialization
cl_platform_id platform;
cl_device_id device;
cl_context context;
cl_command_queue command_queue;
cl_mem bufferA;
cl_mem bufferB;
cl_mem bufferC;
cl_program progam;
cl_kernel kernel;
// 1. Obtaining OpenCL Platforms and Devices
//// 1-1. Obtain a list of avialabel OpenCL platforms
clGetPlatformIDs(1, &platform, NULL);
//// 1-2. Obtain the list of available devices on the OpenCL platform
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
// 2. Creating an OpenCL Context a GPU device
context = clCreateContext(0, 1, &device, NULL, NULL, NULL);
// 3. Creating Command-queues and attach it to compute device
// (in-order queue)
command_queue = clCreateCommandQueue(context, device, 0, NULL);
// 4. Allocating Memory Objects
bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeA, NULL, NULL);
bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeB, NULL, NULL);
bufferC = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeC, NULL, NULL);
// 5. Compiling and Building the OpenCL Program
// 5-1. Create an openCL program object for the context
// and load the kernel source into the program object
program = clCreateProgramWithSource(context, 1, (const char**) &kernel_src,
&kernel_src_len, NULL);
// 5-2. Build (compile and link) the program executable
// from the source or binary for the device
clBuildProgram(program,1, &device, NULL, NULL, NULL);
// 6. Creating Kernel Objects
kernel = clCreateKernel(program, "vec_add", NULL);
// 7. Setting the Arguments of the Kenrel
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &bufferA);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &bufferA);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &bufferA);
// 8. Preparing the Input Data
clEnqueueWriteBuffer(command_queue, bufferA, CL_FALSE, 0, sizeA,
hostA, 0, NULL, NULL);
clEnqueueWriteBuffer(command_queue, bufferB, CL_FALSE, 0, sizeB,
hostB, 0, NULL, NULL);
// 9. Launching the Kernel
// 9-1. Specify the number of total work-items in the index space/a workgroup
size_t global[1] = {SIZE} // index space
size_t local[1] = {16} // # of workitems in a workgroup
clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,
global, local, 0, NULL, NULL);
// (10) Wait until the kernel command completes
// (no need to wait because the command_queue is an in-order queue)
// clFinish(command_queue) // wait done of previous queued commands.
//10. Obtaining the Result from the Device
clEnqueueReadBuffer(command_queue, bufferC, CL_TRUE, 0, sizeC,
hostC, 0, NULL, NULL);
아래 그림은 OpenCL이 Runtime 중에 수행하는 과정을 나타내었다.

Host thread는 여러 Command queue에 kernel를 넣을 수 있다. OpenCL Runtime에서는 Command-queue에서 Command를 꺼내 Compute device로 issue 한다. Command-queue의 type에 따라 in-order 혹은 out-of-order로 수행될 수 있다. 물론 Command-queue 내부에서의 Command간의 dependences가 해결된 상황에서만 Command를 꺼내 issue 할 수 있다.
Issue된 Kernel은 workgroup 단위로 Compute Unit으로 전달한다.
앞서 이야기 했듯이, Work group 내부에서는 synchronization이 가능하고, Work group 간에는 불가능하다. Work group 내부에서의 synchronization은 아래 그림과 같이 barrier를 통해서 가능하다.
// barrier
__kernel foo(__global float *a, __local float *b){
int id = get_global_id(0);
if (id == 0) {
barrier(CLK_GLOBAL_MEM_FENCE);
} else{
b[id] = a[id];
}
// error
}
하나의 Command Queue 안에서도 Barrier가 가능하다.
Out-or-order queue 일 때, barrier command를 사용하면 해당 Command 이전에 Kernel 실행이 완료되고 나서 다음 Kernel를 실행해야 한다.
물론, 여러 Command Queue 간에도 barrier가 가능한다.
다른 Command queue에 들어 있는 Kernel 중 지정된 kernel의 실행이 모두 끝난 이후, 다음 kernel를 수행할 수 있다.
OpenCL의 Memory Consistency model은 Relaxed memory consistency model로, 항상 메모리가 constistency를 유지하지 않다. workgroup 내부에서 work-item 간에 local/global memory는 work-group barrier를 통해서 consistency를 유지한다.
Consistency를 강제하는 synchronization point는 아래와 같다.
1. clFinish
2. work-group barreir
3. Command-queue barriers
4. Event synchronization
[1]:https://www.khronos.org/assets/uploads/developers/library/2012-pan-pacific-road-show-June/OpenCL-Details-Taiwan_June-2012.pdf
[2]: Sowa, P. and Jacek Izydorczyk. 2020 "Darknet on OpenCL: A Multi-platform Tool for Object Detection and Classification" Preprints. https://doi.org/10.20944/preprints202007.0506.v1
[3]: https://slideplayer.com/slide/3277758/
'IT_Study > CS_Study' 카테고리의 다른 글
| [Parallel Computing] (20) CUDA (0) | 2024.05.26 |
|---|---|
| [Parallel Computing] (19) Register Allocation (0) | 2024.05.26 |
| [Parallel Computing] (18) GPU Architectures (0) | 2024.05.26 |
| [Parallel Computing] (17) Memory Consistency (0) | 2024.05.25 |
| [Parallel Computing] (16) Tiling for Matrix Multiply (0) | 2024.05.25 |

댓글