VLSI 기술 발전으로 이전 보다 하나의 칩안에 넣을 수 있는 로직들이 더 많아졌다. 이 점을 활용하여 싱글 코어의 성능을 높이기 위하여 주요한 두 가지 기술을 도입하였다. 하나는 Instruction pipeline 이며, 또 다른 하나는 On-chip cache이다.
Instruction Pipeline은 여러 Instruction을 동시에 수행하는 방법이다. 이를 통해서 instruction 처리량을 향상 시킬 수 있다.
아래 그림과 같이 예를 들어 옷을 세탁하는 과정을 3가지로 이뤄지고, 세탁해야할 옷 더미 A, B, C, D 4개가 존재한다. 왼쪽은 옷더미 A,B,C,D를 순차적으로 처리하는 방법이고, 오른쪽은 세탁하는 과정에서 필요한 자원(세탁기, 건조기, 옷 개기)이 있으면 이전 옷 더미의 세탁이 끝나지 않더라도 수행하여 처리하는 방법이다. 오른쪽 방법을 사용하면 세탁기, 건조기, 옷 개기를 최대한 동작시킬 수 있으며, 이로 인해 각각에 소모되는 시간을 어느 정도 중첩시킬 수 있다.
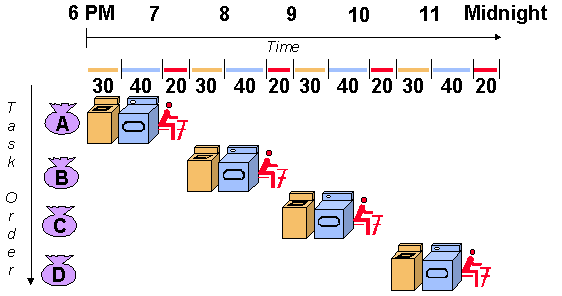
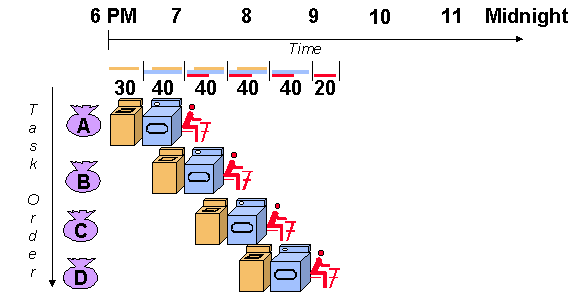
위의 예시에서는 옷 더미 A,B,C,D를 세탁할 때, 세탁에 필요한 자원만 있으면 바로 수행이 가능했다. 그러나 Instruction을 동시에 수행할 때는 그렇지는 않다. 그 이유는 Instruction 간에 dependences가 존재하기 때문이다. Instruction은 프로그램의 기능에 따라서 순차적으로 변환된다. 이 Instruction의 sequence를 순차적으로 실행하면, 프로그램의 의도대로 실행이 되는 것이다. 이 sequence를 지키지 않고, 동시에 수행하려면 Instruction 간의 순서 관계를 고려해야 한다. 이 순서 관계를 dependences라고 이야기하며, Instruction에 사용되는 data와 관련된 dependences와 branch(eg, if 문)으로 인하여 발생되는 control dependences로 나눌 수 있다.
Data dependences는 각각의 Instruction에서 읽거나 쓰는 data가 동일한 경우를 의미한다. 이를 경우에 따라 4가지로 구분할 수 있다. 아래와 같이 Previous Instruction와 Current Instruction이 동일한 data를 읽고 쓰는 경우를 Flow Dependence/Anti Dependence/Output Dependence/Input Dependence로 구분할 수 있다.
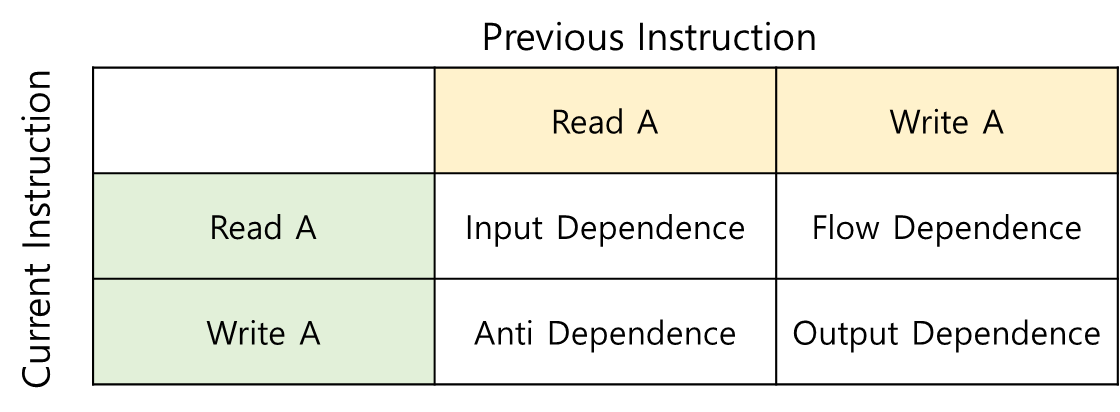
첫 번째는 Flow dependence(RAW)로 이전 Instruction에서 쓰는 데이터 영역을 다음 Instruction이 읽어 오는 것을 의미한다. 이 dependence는 회피하기가 어려워서 True dependence라고 하기도 한다.
두 번째는 Anti dependence(WAR)로 이전 Instruction에서 읽은 데이터 영역에 다음 Instruction이 쓰는 것을 의미한다. 이 dependence는 다음 Instruction이 쓰는 영역을 다른 곳으로 옮기고, 이전 Instruction이 해당 영역을 읽을 수 있으면 회피할 수 있다. 그래서 이를 False dependece라고 한다.
세 번째는 Output dependence(WAW)로 이전 Instruction에서 쓰는 데이터 영역을 다음 Instruction도 쓰는 것을 의미한다. 각 Instruction이 쓰는 영역을 다른 곳으로 옮기고, 각 Instruction이 수행되는 시점 마다 어떤 영역에 있는 데이터가 최신인지를 파악하면 이를 회피 할 수 있다. 그래서 이를 False dependence라고 한다.
네 번째는 Input dependence(RAR)로 각 Instruction이 서로 같은 영역을 읽어 오는 것을 의미한다. 데이터 변경이 이뤄지지 않았으므로 어떤 Instruction이 먼저 읽어도 관계 없다. 따라서 이는 실제 dependence는 아니며, cache를 사용할 경우, 두 번째로 읽을 때는 Cache hit이 발생한다.
Control dependences를 살펴보기 위하여, 우선 Basic Blocks의 개념에 대해서 알아보자.
Basic Blocks은 일반적으로 단일 진입점과 단일 종료점을 갖는다. 진입점은 블록의 첫 번째 Instruction 이고, 종료점은 마지막 Instruction이다. 중요한 점은 Basic Block 내부에는 중간에 분기가 없다. 즉, Basic Block 내부에서는 분기(Branch) Instruction (조건부 또는 무조건적인 점프 등)가 없다. 분기(Branch) Instruction 를 만나면 새로운 기본 블록의 시작점이거나 현재 블록의 끝점을 나타낸다.
Basic block을 정의하는 leader를 식별하는 규칙은 다음과 같다
1. The first instruction is a leader.
2. Any instruction that is the target of a conditional or unconditional jump is a leader.
3. Any instruction that immediately follows a conditional or unconditional jump is a leader.
Basic Block 은 프로그램 내에서 실행의 원자적 단위(Atomic execution) 로 간주된다. 이는 Basic Block 내의 제어 흐름은 항상 선형적이며, 각 Instruction 를 순차적으로 실행하고 어떠한 분기나 점프도 없이 진행되는 것을 말한다.
Basic Block 은 제어 흐름 그래프(Control Flow Graphs, CFGs)를 구성하는 데 사용된다. 제어 흐름 그래프에서 각 Basic Block 은 노드에 해당하며, 노드 간의 엣지는 가능한 제어 흐름 경로를 나타낸다.
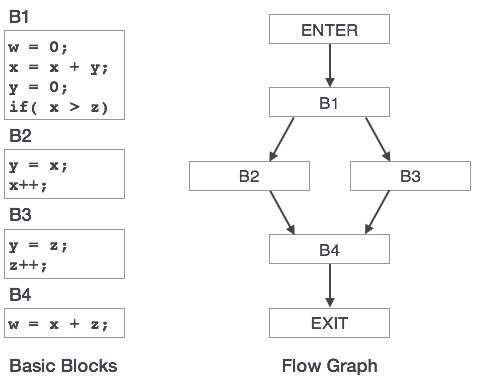
Control dependences는 위의 Flow graph의 B1와 B2/3에서 볼 수 있다. B2와 B3 중 어떤 것이 실행되느냐는 B1의 결과 같이 달라진다. 특정 Basic block의 결과 값에 따라 다른 Basic block의 실행 여부가 결정될 때 Control dependeces가 있다고 한다.
그럼 이 dependences가 존재할 때, Instruction Pipeline 관점에서는 어떻게 해결 하는 지 알아보겠다.
Instruction의 pipeline은 일반적으로 5개의 stage로 구성된다.
Instruction fetch를 수행하는 IF Stage, Instruction이 이떤 동작인지 확인하고, 필요한 register fetch를 수행하는 ID Stage, Instruction 동작을 수행하는 EX Stage, Memory에 접근하는 MEM Stage, 수행 결과를 Register에 다시 적는 WB Stage로 구성된다.
각 Stage 마다 서로 다른 instruction이 수행되기 때문에, 각 Stage 마다 instruction 간의 data dependences, branch instruction으로 발생하는 Control dependences 그리고 pipeline 구조적인 문제로 바로 수행할 수 없는 경우가 발생한다. 이를 Data/Control/Structural hazards라 한다.
data hazard는 instruction 수행에 필요한 데이터를 당장 사용할 수 없을 경우 발생한다. 예를 들어 I1과 I2가 True dependence일 때, I2는 I1에서 수행된 결과값을 얻기 전까지는 수행(ID Stage 부터)을 할 수 없다. 이 문제를 가장 쉽게 해결하는 방법은 Register file로부터 해당 데이터를 얻을 수 있을 때 까지 기다리는 것이다. Hardware 적으로 이를 기다리게 만들 수도 있고, Software 적으로 no-op를 추가하여 해당 데이터를 얻을 수 있을 시점에 맞춰 다음 Instruction을 수행한다.
그런데 이런 기다리는 방식은 비효율적이다. 최대한 데이터가 필요로 하는 시점까지 수행을 해두고 기다리는 편이 좋다. 이전 Instruction의 WB Stage에서 데이터를 Register에 저장하고, 다음 Cycle에 다음 Instrcution의 ID Stage를 수행할 수 있다. 이 때, Register에 동일한 주소의 데이터를 쓰고 읽는 것을 동시에 수행할 수 있다면, 이전 Instruction의 WB Stage와 다음 Instruction의 ID Stage는 동시에 수행할 수 있다. 추가적으로 해당 데이터를 Register file에 적고 다시 읽는 것 보다 읽는 과정을 생략하고, 데이터를 바로 사용할 수 있도록 해줄 수도 있다. 그렇다면 이전 Instruction의 WB Stage와 다음 Instruction의 EX Stage를 동시에 수행할 수 있다.
Control hazard는 branch 동작으로 인해 발생한다. 특정 Instruction의 결과에 따라 일정 개수의 Instruction이 수행되지 않을 수 있다. 즉 이전 Instruction의 WB Stage 전까지는 다음 Instruction의 수행여부를 알 수 없다. 가장 간단한 방법은 역시 기다리는 것이다. 그런데 잘 살펴보면, 수행되지 못하는 Instruction은 branch 와 관련 것들이다. 따라서 branch와 관련 없는 Instruction은 수행가능 하기 때문에, 이런 Instruction을 찾아서 수행할 수 있다.
Instruction을 순차적으로 수행할 것인가, 아니면 순서에 상관없이 수행할 것이에 따라 in-order/out-of-order execution으로 나뉠 수 있다. 기본적으로 in-order 수행은 말그래도 순차적으로 pipeline을 수행하는 것이다.Pipeline의 모든 stage가 순차적으로 수행된다. 그런데 이렇게 되면 앞 Instruction으로 인하여 뒤 Instruction이 수행되지 못하는 상황도 발생한다. 이를 해결하고자 out-of-order execution을 수행한다. Instruction을 Reservation station에 기록해두고, 수행가능한 Instruction이 발생할 때마다 수행을 한다. 이때, ID Satge를 지나간 Instructions들은 issue가 되었다고 이야기하며, Instruction의 모든 operands가 사용 준비가 완료되었을 때, Reservation station에서 Excute Unit으로 전달되는 것을 Dispatch라고 말한다.
Tomasulo's algorithm의 Instruction 수행 방식은 In-order Issue -> Out of order dispatch -> Out-of-order execution -> In-order commit으로 진행된다. In-order commit은 Instruction 순서를 마지막 단계에서 다시 순차적으로 맞춰주는 데, Reorder buffer를 사용하여 수행된다. Instruction Issue 순서 대로 Reorder buffer에 쓰여지고, 수행은 Out-of-order로 이뤄지지만, 최종 완료는 순서를 지켜서 수행된다. 이 때, Reorder buffer에서 Instruction이 제거되나 Commit이 되면 buffer slot을 비우는 데 이를 Retirement라고 한다.
Superscalar Processors는 Instruction level Parallelism를 활용하기 위해 한번에 한 Instruction 씩 Fetch/Decode를 수행하지 않고, 여러 개의 Instruction을 동시에 Fetch/Decode를 수행한다. 일반적으로 최대 4개의 Instruction을 동시에 Fetch/Decode를 수행한다. 를 활용한 것이다.
VLIW(Very Long Instruction Word) Processors는 여러 Instruction을 하나의 긴 Instruction으로 변환하여 수행하며, Compiler가 dependences를 고려하여 수행한다.
[1] : http://www.ece.arizona.edu/~ece462/Lec03-pipe/
[2] : https://lolki.tistory.com/4
Control Flow Analysis
CFA Control Flow Analysis 정리 1. Control Flow Analysis 컴파일러의 분석에는 두가지로 나누어진다. Control flow analysis 제어 흐름을 분석한다. Data flow analysis 데이터의 흐름을 분석한다. 이러한 분석을 하는 이
lolki.tistory.com
'IT_Study > CS_Study' 카테고리의 다른 글
| [Parallel Computing] (9) Parallelism (1) | 2024.04.20 |
|---|---|
| [Parallel Computing] (8) Loop Carried Dependence (0) | 2024.04.19 |
| [Parallel Computing] (6) Processes and Threads (0) | 2024.04.17 |
| [Parallel Computing] (5) Floating Point Representations (0) | 2024.04.16 |
| [Parallel Computing] (4-3) Arithmetic Operation(2) (0) | 2024.04.14 |



댓글