이번 글에서는 Parallel Computing을 수행할 Application에 대해서 알아보려고 한다.
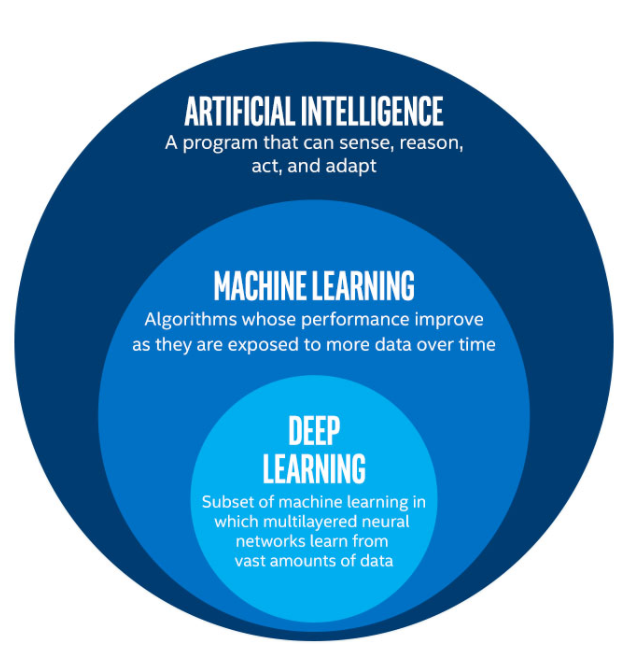
Parallel Computing의 중요성이 대두되는 이유는 인공지능(AI)의 발전과 밀접하게 연관되어 있다. 인공지능은 지능을 가지는 컴퓨터를 만드는 과학과 공학를 이야기하며, 즉 소프트웨어 및 하드웨어에서 인간 수준의 지능을 보유한 개체를 만드는 것이라 할 수 있다. 인간 수준의 지능은 인간이 추론하고 생각할 수 있는 높은 수준의 인지 능력에 초점을 맞추는 것을 의미한다. 그런데 아직까지는 인간 수준의 지능을 가지는 컴퓨터를 만들기는 어렵다. 현재 AI 기술이라고 하면 기계학습(Machine Learning)에 가깝다. 기계 학습은 AI의 하위 분야로써 컴퓨터를 새로 프로그래밍하지 않고도 학습할 수 있는 기능을 제공하는 것을 말한다. 기계 학습에서의 알고리즘은 더 많은 데이터에 노출 될 때 더 나은 성능을 발휘하도록 스스로를 조정하는 것이다.
이러한 기계 학습 알고리즘 중에서 최근 몇년간 뛰어난 성능을 보인 것이 Deep Learning이다. Deep Learning은 기계학습의 하위 분야로써 인공 신경망을 기반으로 구성되어 있다. 인공신경망은 신경계 및 뇌와같은 생물학적 신경망에서 영감을 얻은 컴퓨팅 시스템이다. 인공 신경망은 다수의 상호 연결된 처리요소(인공 뉴런)들로 구성되어 있다. 이 때, 두 개 이상의 은닉층(Hidden layer)가 있는 신경망을 Deep Neural Networks(DNN)이라고 한다. DNN은 작업에 특정적인 규칙을 통해 프로그래밍 된 것이 아니라 예제를 통해 작업을 수행하는 방법을 학습할 수 있다. 즉, 데이터의 패턴 발견 및 발견한 패턴을 기반으로 예측 및 의사 결정을 수행한다.
그런데 이 Deep Learning과 관련된 이론이 최근에 나온 것이 아니라 이미 1980년대에 확립되었다. 그런데, 그 당시에는 실용적이지 않은 방법이었다. 여러 가지 이유가 있었지만, Data 및 Computing 관점에 살펴보면, 레이블이 지정된 데이터 셋이 현저히 적었으며, 과거의 컴퓨터는 지금보다 수만배나 느렸기 때문이다. 다시 말하면 현재는 인터넷에 의한 학습데이터의 증가로 인하여 데이터가 풍부해졌고, 컴퓨터 시스템의 발전으로 매우 빠른 컴퓨팅이 가능해졌다.
AI 발전의 한 예로 Language Model을 꼽을 수 있다. 언어 모델은 m개 단어로 이루어진 Sequence가 주어졌을 때, 이 Sequence가 실제로 나타날 가능성(확률)을 계산한다. 즉, 문장 내의 앞서 등장한 단어를 기반으로 뒤에 어떤 단어가 등장해야 문장이 자연스러운지 판단하거나 어떤 문장이 주어지면 뒤에 어떤 문장이 와야 자연스러운지 판단한다. 주로 딥러닝 기반의 모델이 뛰어난 성능을 보인다. 이런 언어 모델의 파라미터 수는 지난 몇 년동안 극적으로 증가하고 있고, 지속적으로 더 큰 언어 모델을 개발하고 있다.
2020년에 OpenAI가 GPT3를 발표하였다. GPT3는 LLM(Large Laanuage Model)로써 1750억개의 파라미터, 4990억개의 토큰를 가지고 314000 EXA-FLOPS (single-precision floating-point representation)의 컴퓨팅 성능이 필요하다. 이를 하나의 NVIDIA V100 GPU로 학습을 수행하면 355년이 걸린다. 학습 시간을 줄이고자 클라우드의 수천개 NVIDIA V100 GPU를 이용하였고, 그 비용은 무려 $4.6M(약 60억)에 달한다.

컴퓨터 시스템 관점에서 조금더 살펴보면, 부족한 Computing power는 large-cluster-level computing를 도입하므로 극복하였으나 이를 위한 비용이 매우 컸다. GPT-3에 사용된 Parameter의 크기가 매우 크므로, 한 개의 GPU의 메모리에 모두 담을 수 없었다. 그러므로 Parallelism이 필요했다. 또한 GPT-3의 Training dataset 또한 매우 크므로 노드간 scacle strogate I/O가 필요했다. 이런 문제들은 고성능 컴퓨팅에서 늘 다루던 문제이며, 지속적으로 이를 해결하기 위한 방법들을 연구하고 있다.
초거대 ai 모델 학습을 위해서는 슈퍼 컴퓨터 급(데이터 센터와 같은 규모의) 대규모 GPU 클러스터가 필요하다. 많은 계산 메모리 자원이 낭비되고, 에너지 소모 및 이에 따른 탄소 배출도 막대하다. 향후 AI의 발전은 기존 기법의 번형 혹은 새로운 방법을 개발해 "현저하게" 계산에 효율적인 방법을 요구할 것으로 예측된다. 이에 실행 플랫폼의 성능을 최대화하고 전력소모를 최소화할 수 있는 자동 병렬화/최적화 기술 개발이 필요하다.
[1] https://ai.stackexchange.com/questions/15859/is-machine-learning-required-for-deep-learning
[2] https://fiw.thws.de/en/news/thema/neuer-gpu-cluster-fuer-ki-anwendungen-an-der-fakultaet/
'IT_Study > CS_Study' 카테고리의 다른 글
| [Parallel Computing] (4-2) Arithmetic Operation(1) (0) | 2024.04.14 |
|---|---|
| [Parallel Computing] (4-1) Binary Representation (2) | 2024.04.13 |
| [Parallel Computing] (2-2) Parallel Processing이란 무엇일까? (2) | 2024.04.12 |
| [Parallel Computing] (2-1) Parallel Processing이란 무엇일까? (2) | 2024.04.12 |
| [Parallel Computing] (1) Supercomputer이란 무엇일까? (0) | 2024.04.12 |


댓글