mAP(Mean Average Precision)은 Object detection Task의 성능을 평가하기 위한 Matrix 중 하나이다. 경연에서도 이 Matrix을 이용하여 성능평가를 진행하였다.
mAP를 계산하는 방법을 알아보기 앞서, Object detection Task의 성능을 어떻게 평가해볼지 생각해보자. 성능 평가라고 하면, 정답(Ground Truth)과 예측(Estimation)을 비교하여 많이 일치할수록 성능이 높다고 생각한다.
고양이와 개를 구분하는 Image Classification Task를 수행한다고 생각해보자. 고양이 사진을 입력으로 하고 이 사진이 고양이라고 예측하면 성공했다고 볼 수 있다. 마찬가지로 강아지 사진을 입력으로 하고 이 사진을 강아지라고 예측하면 성공했다고 볼 수 있다. 이를 숫자로 표현하면, 100장의 고양이, 강아지 사진을 입력으로 하여 정답과 동일한 예측을 90장 성공했다면 90/100 -> 90%의 정답률을 보인다고 할 수 있다.
얼굴의 위치를 찾는 Face detection Task를 수행한다고 생각해보자. 사람들의 얼굴이 존재하는 사진을 입력으로 하고 이 사진 속의 얼굴의 위치를 제대로 찾는 다면 성공했다고 볼 수 있다. 여기서 정답은 얼굴의 위치이다. 일반적으로 위치는 네모 박스로 표현된다. 예측한 위치(파랑)와 정답 위치(빨강)가 동일할 수록 성공했다고 볼 수 있다. 이걸 어떻게 수치로 나타낼 수 있을 까? 정답 네모 박스와 예측한 위치의 네모 박스가 겹치는 영역(노랑)을 계산하는 방법으로 구해볼 수 있다.
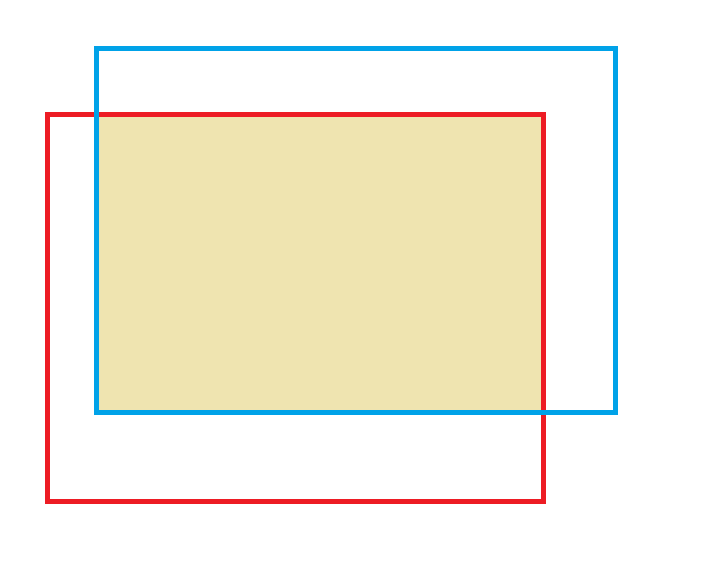
IOU(intersect over Union)는 해당 영역을 이용하여 성능을 측정하는 지표이다. IOU는 정답 영역과 예측 영역의 교집합(노랑)과 정답 영역과 예측 영역의 합집합 비율로 계산할 수 있다. 비율이 1에 가깝다는 말은 정답 영역과 예측 영역이 거의 같다는 것을 의미한다.
그런데 만약 예측을 하지 못 했다면 어떻게 될 까?까? 예측 영역 자체가 없으니 영역의 크기는 '0'이므로 IOU는 0이 될 것이다. 반대로 정답 영역이 없는 곳을 예측했다면 어떻게 될 까? 정답 영역 자체가 없으니 영역의 크기는 '0'이고 마찬가지로 IOU는 '0'이 될 것이다.
다른 경우이지만 IOU는 모두 '0'으로 계산이 된다. 이를 구분해서 성능 측정하는 방법이 있다.
첫번째 경우는 정답은 있지만 이를 예측하지 못한 상황이다. 다시 말하면 여러 정답 중에 몇 개나 찾았는 지를 측정하면 된다. 이를 Recall, 검출율이라고 부르며 정답이라고 예측한 숫자와 정답의 수의 비율이다. 예를 들어 10명의 사람이 있었지만, 10명 중에 5명만 정확하게 검출 했다면 5/10 => 50%의 검출율을 가진다고 이야기할 수 있다.
두 번째 경우는 예측을 했지만 정답이 없었던 상황이다. 다시 말하면 예측한 것들 중에 정답이 얼마나 있었는 지를 측정하면 된다. 이를 Precision, 정확도라고 부르며 예측한 숫자와 정답을 맞힌 수의 비율이다. 예를 들어 10명의 사람이 있었다고 예측했지만 5명만 정답이었다면 5/10 => 50%의 정확도를 가진다고 이야기할 수 있다.
그렇다면 2가지 Matrix(검출율, 정확도) 중에 어떤 것을 선택해야하는 가?
하나의 Matrix를 선택해서 사용하기에는 각 지표의 맹점들이 존재한다.
Recall, 검출율의 경우, 단지 정답을 찾기만 하면 되므로 무수히 많은 위치를 예측한다면 어느 한 위치는 정답과 가까울 것이다. 이렇게 되면 Recall 값은 크지만, 정답을 찾지 못한 무수히 많은 예측이 존재한다. 예를 들어 10명의 사람이 존재하는 사진이 있는데, 1000개의 예측을 수행하여 10명을 찾았다면 Recall 값은 1이지만 990개의 실패한 예측 위치가 존재한다.
Precision, 정확도의 경우, 예측한 것들 중에 정답인 비율이기 때문에 예측 자체를 매우 조금만 하는 것이다. 10명의 사람이 존재하는 사진이 있는데, 가장 확률이 높은 예측 1개만 수행해서 정답을 맞힌 경우 Precision 값은 1이지만, 9명의 사람을 검출하지 못했다.
서로 다른 상황에서의 맹점을 가지고 있기 때문에, Recall와 Precision은 일반적으로 서로 반비례 관계를 가진다.
이런 맹점들을 해결하기 위하여 Recall과 Precision 모두를 사용하는 방식을 사용한다. Recall과 Precision 모두 예측한 위치에 따라 그 값이 달라진다. 한 개의 이미지에서 1000개의 위치를 예측했다면, 1000개를 정답일 확률로 표현하여 정렬한다. 일정 확률(Threshold) 이상인 것만 예측에 성공했다고 가정하고, Recall과 Precision을 계산한다. Threshold 값에 따라 계산된 Recall과 Precision을 아래와 같이 2D Graph로 표현할 수 있다. 이를 일반적으로 PR Curve라고 부른다.

이 Graph를 이용하여 Average Precision이라는 Matrix를 계산할 수 있다. AP는 PR-Curve의 면적을 계산하므로 구할 수 있다.
그럼 Object detection에서는 사용하는 mAP는 어떤 것일 까?
Face detection의 경우, 얼굴이라는 1가지 Class를 가지고 검출을 수행한다. 그런데 Object detection은 여러 가지 물체를 검출하는 Task이기 때문에 Multi-class를 가지고 있다. 따라서 Class 별 AP를 모두 계산한 후, 이를 평균 낸 것을 mAP라고 부른다.
앞선 포스트로 dataset, 성능 지표까지 알아보았다. 다음 포스트에서는 Object detection Algorithm을 수행하는 기능 별로 나누는 법에 대해서 알아보려고 한다.
* Reference
[1] Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network
'IT_Study > AI_Study' 카테고리의 다른 글
| [Object Detection] 02. VOC and COCO dataset (1) | 2022.08.03 |
|---|---|
| [Object Detection] 01. Object Detection History (1) | 2022.08.02 |
| [Object Detection] 00. Object detection이란 무엇인가? (4) | 2022.08.01 |



댓글